A Dirichlet process (DP) is a random probability measure
H : Base distributionα : concentration parameter

Properties (derive from the mean and variance of the Dirichlet distribution)
α→∞ :Var(G(Ai))→0 ,G=H .α→0 :Var(G(Ai))→0 ,Var(G(Ai))→H(Ai)(1−H(Ai)) , similar to Bernoulli distribution.
Constructive definition: Stick-breaking constructioin
βk∼Beta(1,α) θk∼H πk=βk∏k−1l=1(1−βl) G=∑∞k=1πkδθk
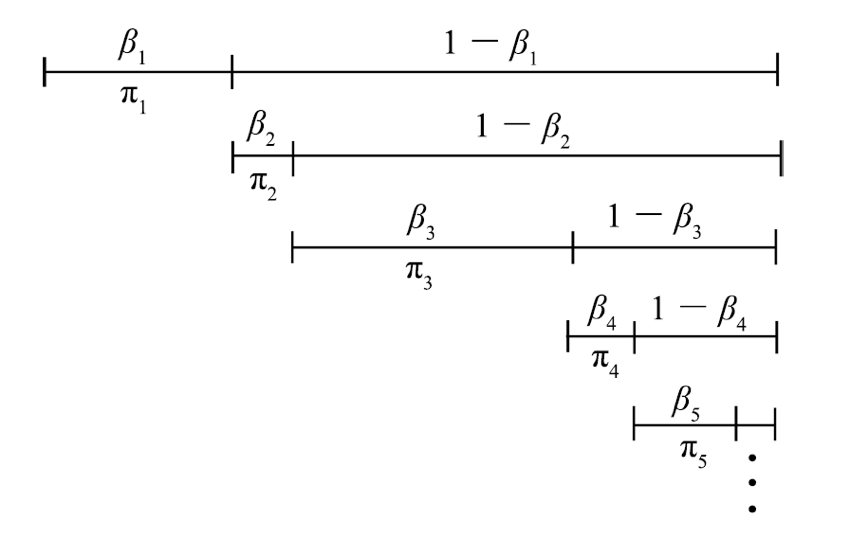
The result stick-breaking sampling has the property:

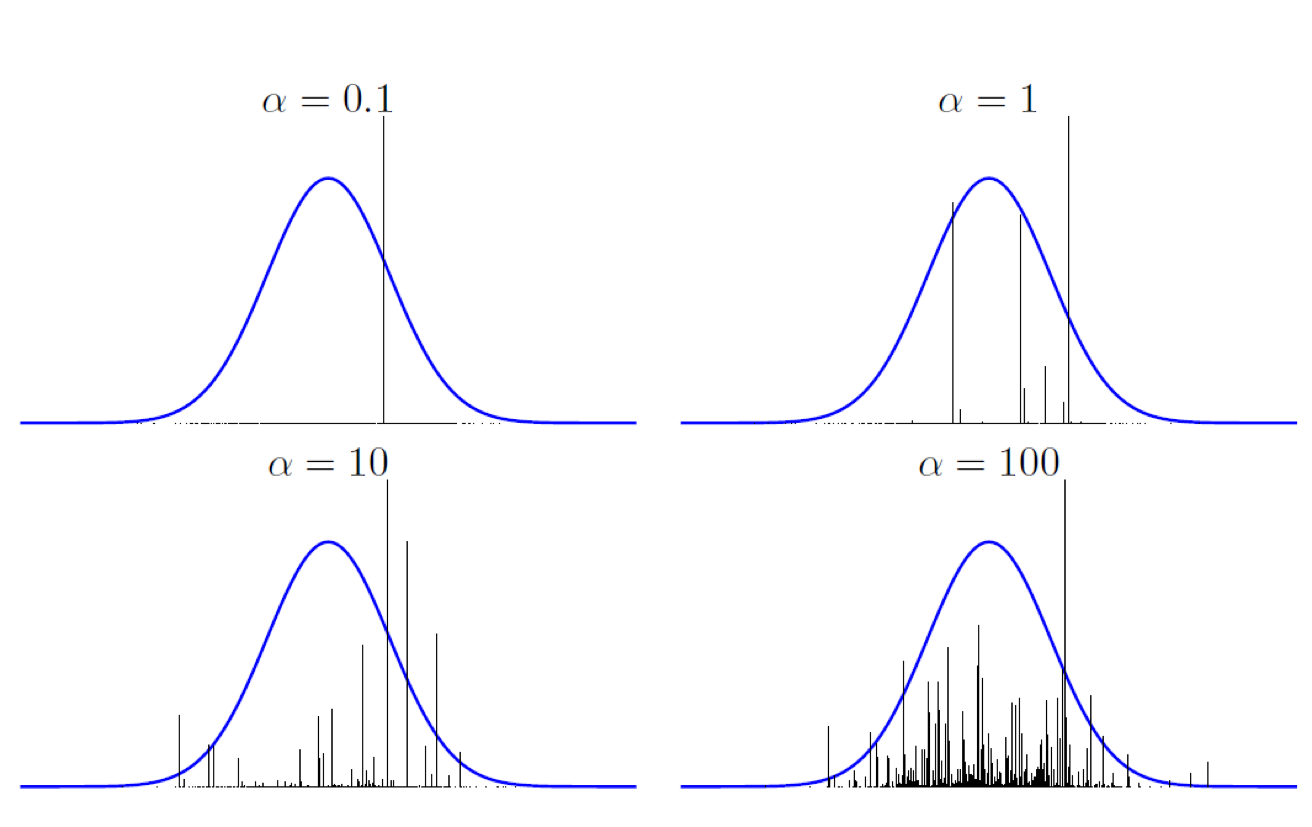
Examples of different
Posterior:
Prediction/Drawing samples:
The prediction can be seen as a Chinese Restaurant Process:
At any positive-integer time
- added to one of the blocks of the partition
Bn , where each block is chosen with probability|b|/(n+1) where|b| is the size of the block (i.e. number of elements), or - added to the partition
Bn as a new singleton block, with probability1/(n+1) .
Reference
Nonparametric Baysian Models: http://videolectures.net/mlss09uk_teh_nbm/
Chinese restaurant process: https://en.wikipedia.org/wiki/Chinese_restaurant_process